
What we learned from building a Semantic Cache for LLMs
How to incorporate Human In The Loop feedback for LLM Applications
Over the last few weeks, we released a Semantic Cache in Twig. The Vertical AI platform for Technical CX teams.
We did not start by building a semantic cache but rather we started working on solving for deterministic AI responses that consider human feedback in LLM-generated responses.
We first started with FineTuning LLMs
Finetuning LLMs with user feedback. This process essentially involves using key-value pairs of questions and suggested responses that you use to train and LLM. You can find more information here https://platform.openai.com/docs/guides/fine-tuning. You can also fine-tune open-source LLMs using LoRA methods like this https://github.com/tloen/alpaca-lora
Drawbacks of Finetuing with user feedback.
Distribution of data: In the early days the use feedback you have is much smaller in size than the LLMs internal knowledge/weights.
Exactness of responses: As answers were generated to lost nuances from feedback
Hallucination: One of the big problems with LLMs is they often confidently hallucinate. So you find yourself asking an LLM to answer from a given retrieval context rather than from its memory. So fine-tuning in this scenario loses its value.
What we found with fine tuning for user-feedback/human-in-the-loop
AI-generated responses were not exact, So while user feedback may be considered the answer may be reworded. Humans expect AI to give exact answers when they have spent the time to correct AI.
Less control over AI
Lack of deterministic outcomes
Here comes the semantic cache
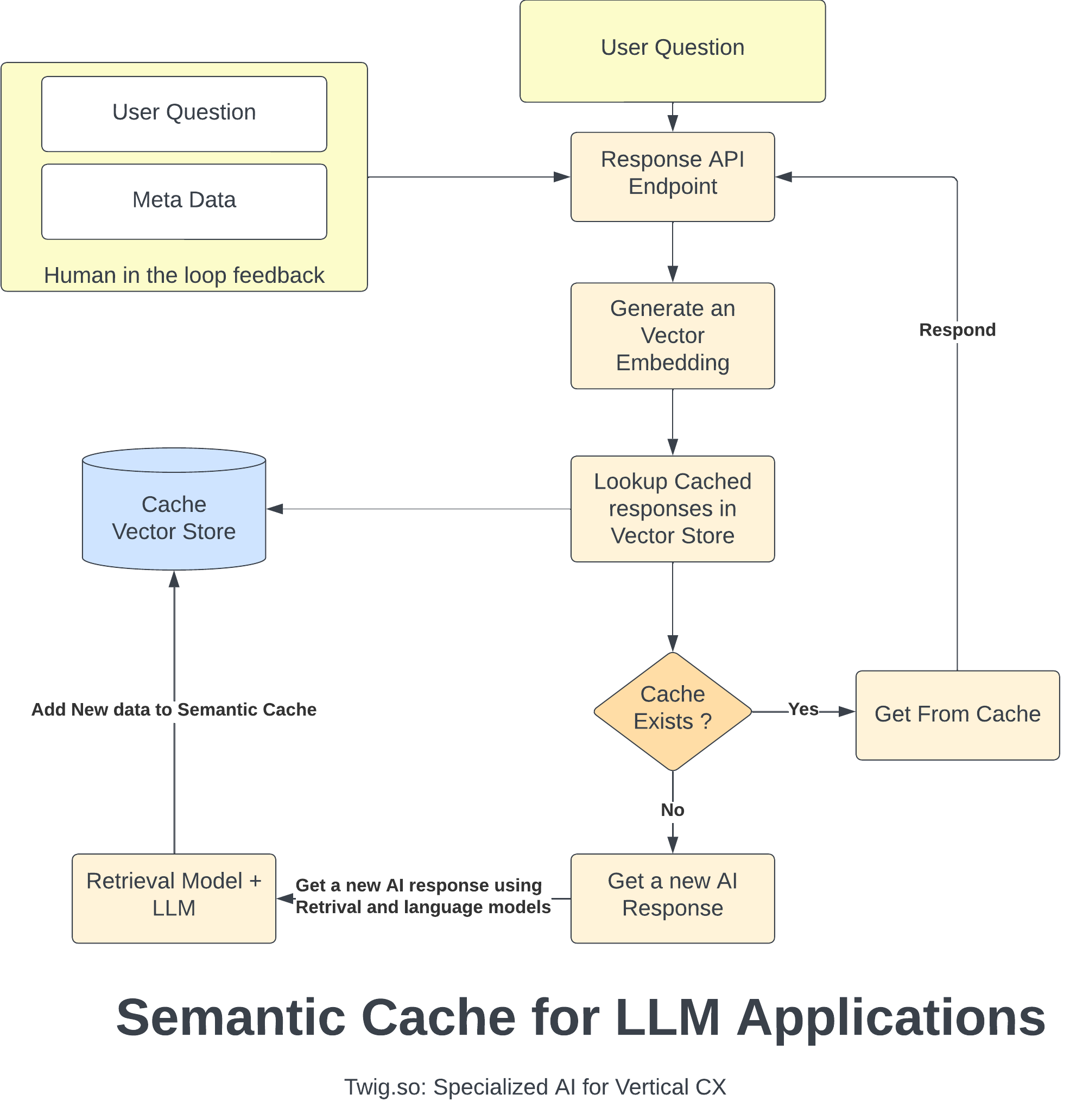
Think of semantic cache as any caching system but rather than looking for an exact match, you are looking for a match similar to previous human feedback. For a semantic cache to work you use a Vector Data Store like https://www.pinecone.io or https://www.tigrisdata.com. You use vector embeddings like ADA2 from OpenAI or open-source models like https://huggingface.co/cambridgeltl/tweet-roberta-base-embeddings-v1. An open-source implementation can be found here https://github.com/zilliztech/GPTCache.
Why we built our own Semantic Cache Layer (SCL)
As we studied this problem, we found that the semantic cache was more fundamental to controlling AI behavior than we initially thought. We were able to have fine-grained control over the user experience. Further, there were multiple use cases for using the SCL. For instance, we could pre-cache large volumes of data, so runtimes were faster. Multi-stage AI like DSP (https://github.com/stanfordnlp/dsp) are very expensive to use in runtime. An SCL can help get faster DSP responses. We could also use SCLs to measure behavior over time.
The result
We are pretty happy with the early results from our custom semantic cache.
Deterministic user responses that include user feedback
Faster AI response times
The ability to create sophisticated scenarios that benefit from response time improvement.s
What are the next steps here?
One of the things we do today that seems rudimentary is confidence ranges. When we look for similar results in the cache we are setting a cosine similarity value of 90% or higher. This does not feel right. As the number is pretty arbitrary. Net new areas of result include better methods of similarity retrieval that can be a prediction rather than a filter.